.svg)
ChatGPT Solved Access to AI. Now Teams Are Trying to Solve Trust.
The first wave of enterprise AI focused on making knowledge accessible. The next wave is focused on making that knowledge trustworthy, verifiable, and specific enough to act on with confidence.
ChatGPT changed what people expect from software. It made natural language a valid interface for complex tasks, put a capable AI assistant in front of millions of people overnight, and fundamentally shifted how individuals approach research, writing, and problem-solving at work. That is not a small thing. It is one of the most significant shifts in workplace productivity in a generation.
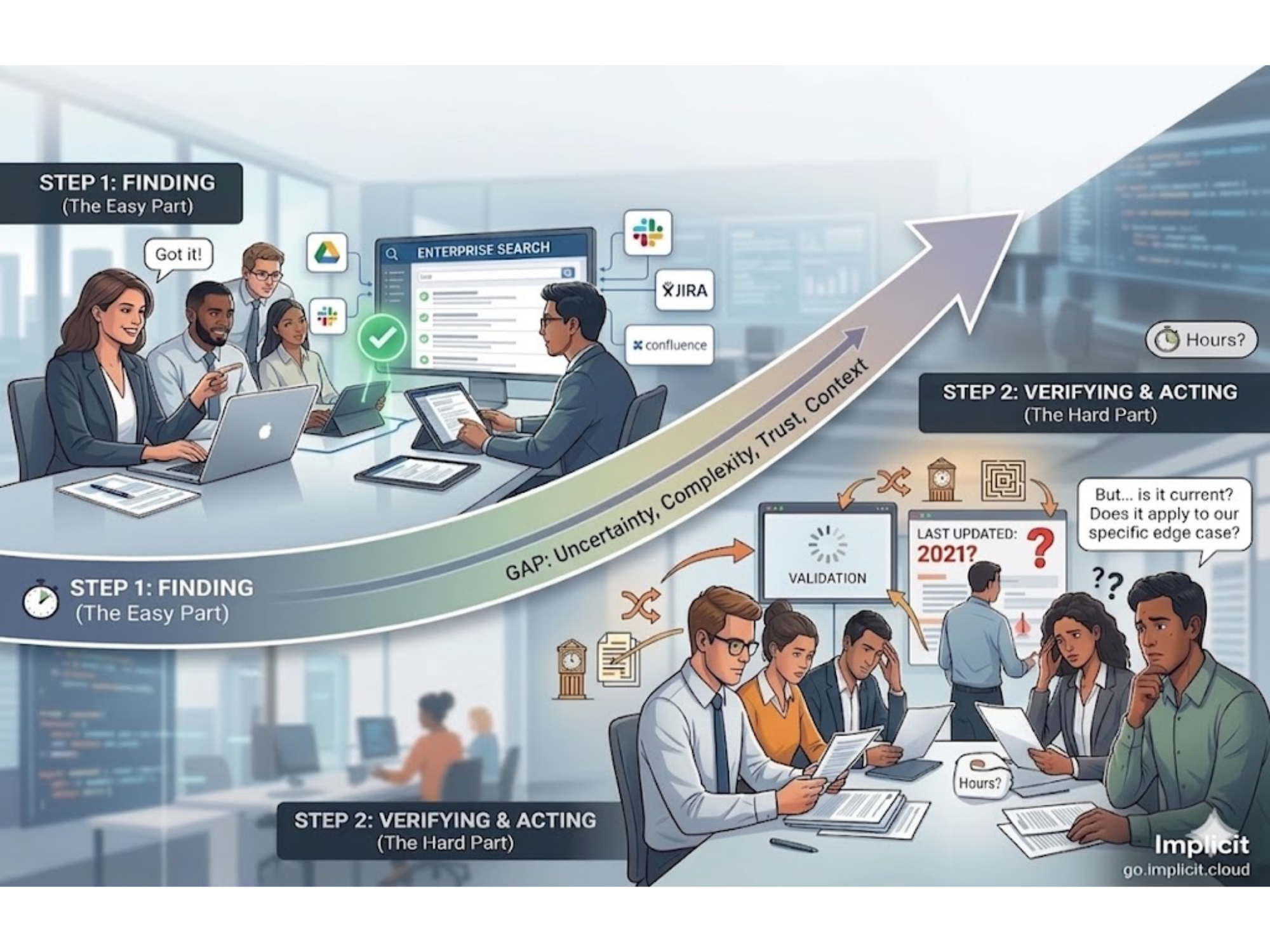
But as teams moved from personal use to business-critical use, a different set of problems started surfacing. And they share a common thread: the gap between an answer that sounds right and an answer you can actually stand behind.
ChatGPT's Core Problem for Business: It Doesn't Know What You Know
ChatGPT is trained on public internet data. It is a generalist, extraordinarily capable across a wide range of topics, but it has no knowledge of your products, your internal procedures, your compliance requirements, or your customer history. When an employee asks a question that touches on any of that, they are getting a best approximation, not a grounded answer.
OpenAI has been working to address this through integrations with tools like SharePoint, Google Drive, and Slack, but connecting data to a general-purpose model and governing how it reasons over proprietary content are two different things. Organizations across financial services, manufacturing, healthcare, legal, and technical support have found that connecting the pipeline is the easy part. Trusting what comes out of it is where things get complicated.
The Hallucination Problem Has Not Gone Away
Studies continue to show that even the most capable versions of ChatGPT fabricate references, misattribute sources, and generate plausible-sounding answers that are factually wrong. A 2025 study found that more than half of citations produced by GPT-4o were either fabricated or contained material errors. GPT-5 has made meaningful improvements, but hallucinations persist, particularly in technical and domain-specific contexts.
For individual use, this is manageable. A person doing background research knows to verify. But in a professional context, where someone is making a decision, drafting a response to a customer, or following a technical procedure, the cost of a confident wrong answer is very different. Most teams have no reliable way of knowing when they are looking at one.
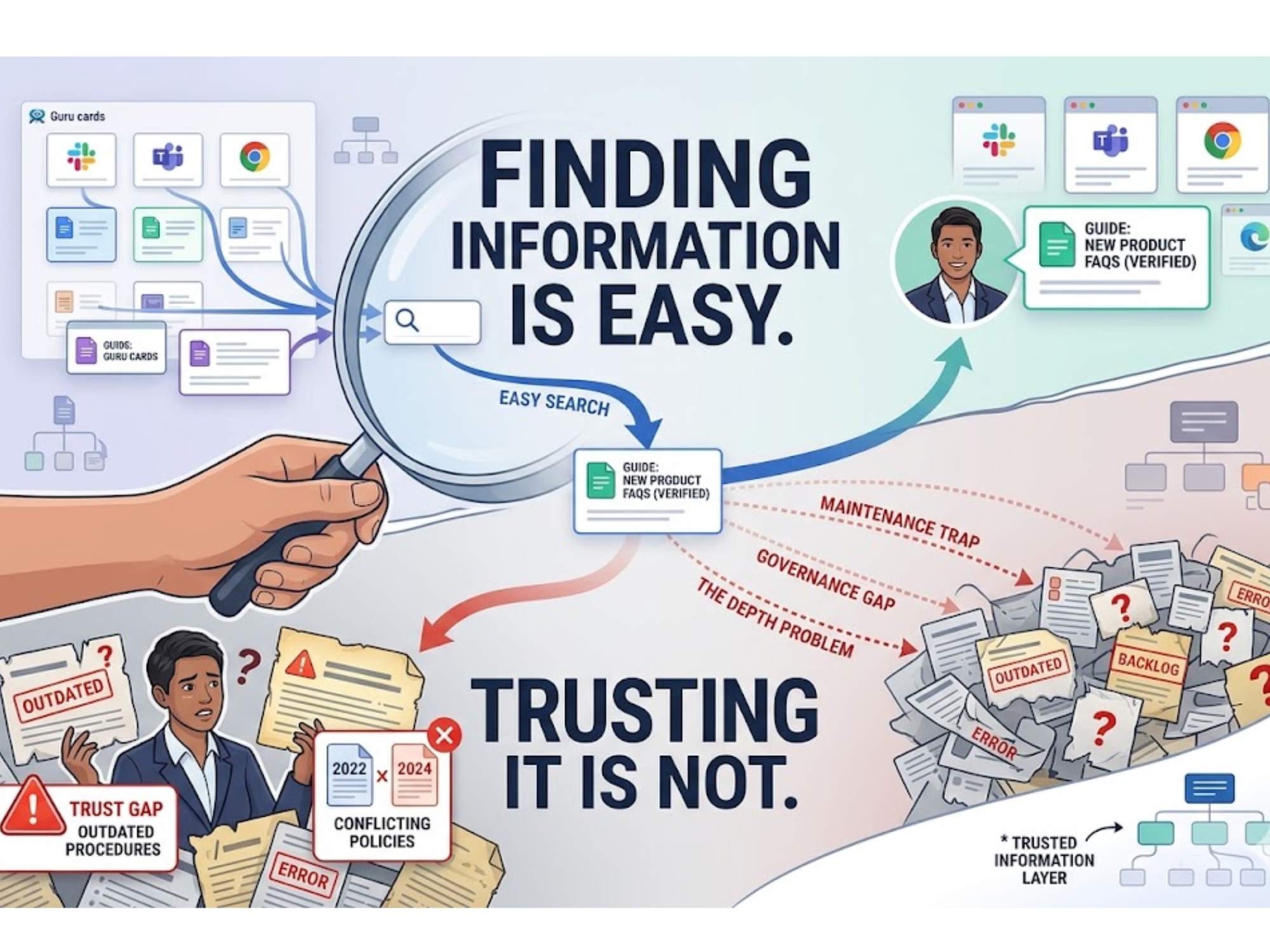
When You Cannot Point to the Source, You Cannot Build Trust
Closely related is the citation problem. ChatGPT typically does not tell you where its answer came from. Even with web browsing enabled, tracing a specific claim back to a specific source is inconsistent at best. This makes it difficult to build organizational confidence in AI-generated answers, especially for teams that need to verify responses before acting on them or sharing them externally.
This matters more in some contexts than others. Support engineers, technical writers, compliance officers, and customer-facing teams in complex industries are increasingly finding that an AI that produces good-sounding answers is less valuable than one that produces verifiable answers. The former is useful for generating drafts. The latter is what enables trust at scale.
Data Security Remains a Genuine Concern
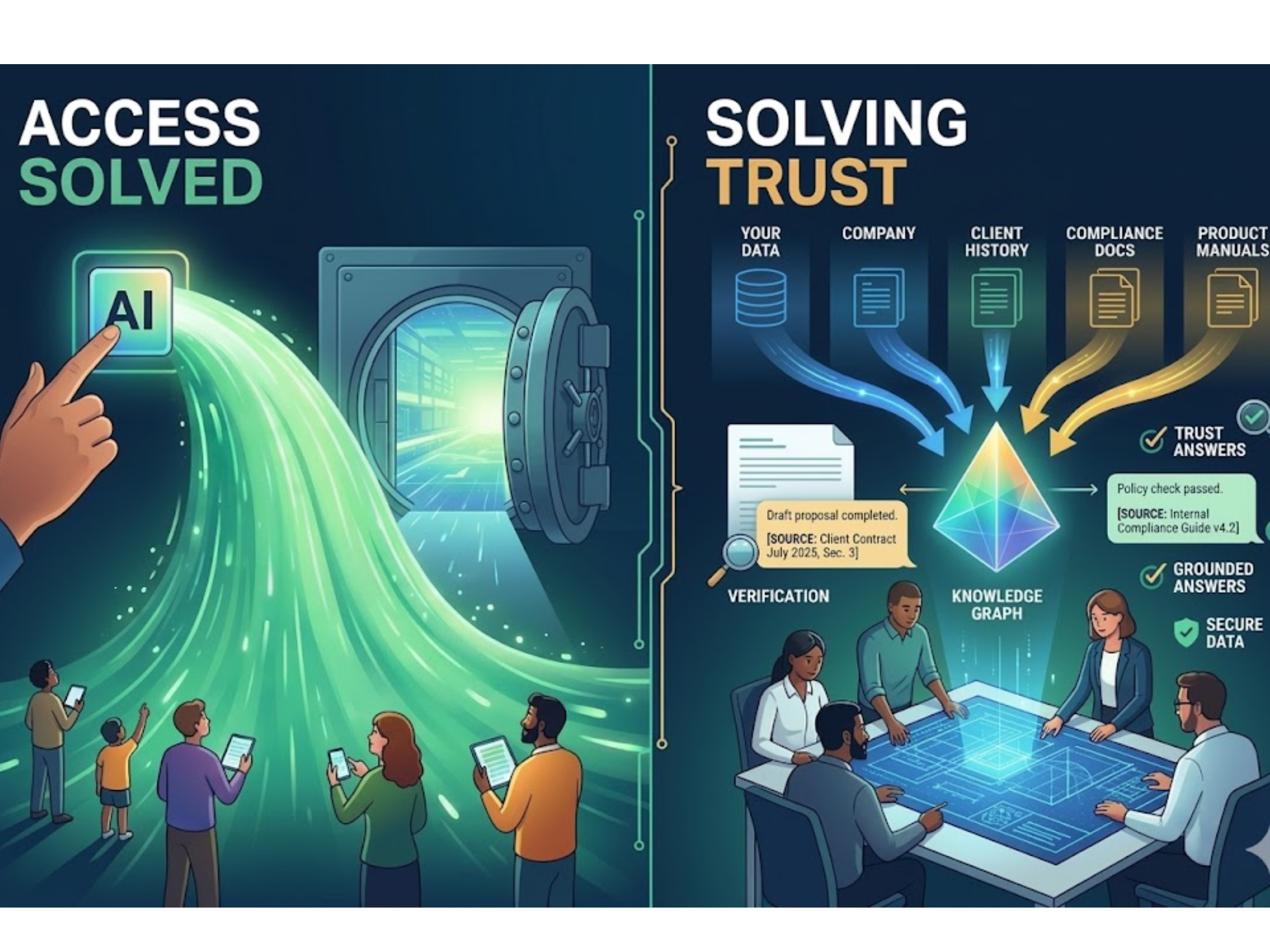
Every prompt sent to ChatGPT travels through OpenAI's servers. For many teams, that is fine. For organizations handling sensitive customer data, proprietary technical documentation, regulated health information, classified material, or anything that carries compliance obligations, it introduces risk that is difficult to fully mitigate. ChatGPT Enterprise offers stronger data protections than the standard product, but it still operates outside the compliance frameworks that many organizations have built around their own infrastructure.
A growing number of teams are asking not just "what can this tool do?" but "can we deploy this inside our own environment, with our own access controls, on the infrastructure we govern?"
Where the Market Is Heading
The first wave of enterprise AI focused on making knowledge accessible. ChatGPT was the clearest expression of that idea, and it delivered. The next wave is focused on making that knowledge trustworthy, verifiable, and specific enough to act on with confidence.
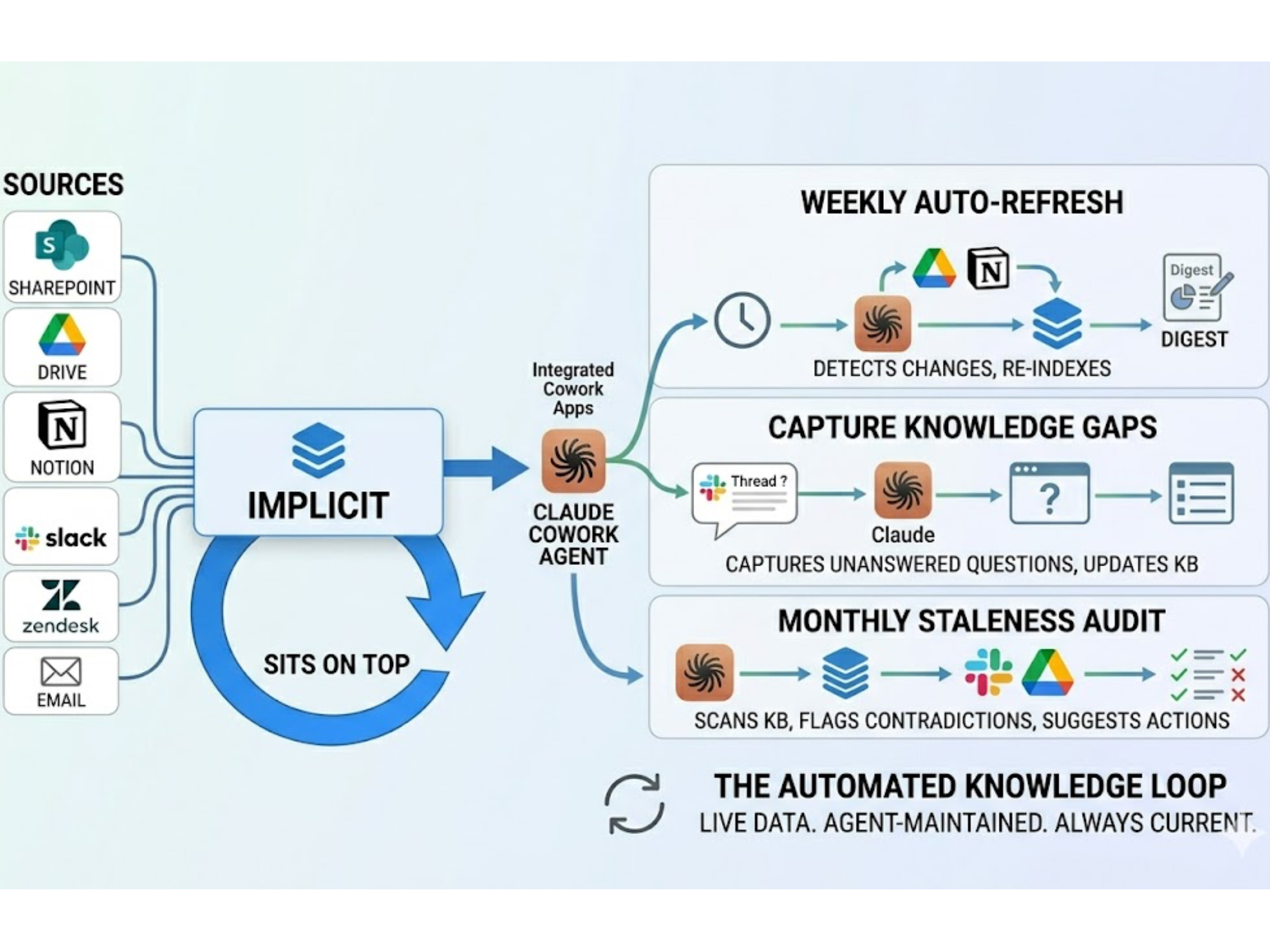
Some systems are now being built around that premise from the ground up: private data environments, answers that cite the exact source they came from, knowledge graphs that model the relationships between your specific products, procedures, and policies rather than generic training data. The question is not whether tools like ChatGPT work. They do. The question is what teams need once general access to AI is no longer the bottleneck.
Implicit was built for that next problem. If you want to see how the two approaches compare across specific capabilities, this covers it in detail.